Wir haben im vorigen Kapitel ein gefiltertes Spektrogramm für einen Songs erstellt. Wie können wir dieses Spektrogramm nun effizient speichern und nutzen? Darin liegt die eigentliche Stärke von Shazam. Um das Problem zu verstehen, gehen wir von einer vereinfachten Situation aus: Wir suchen nach einem Song, indem wir direkt sein gefiltertes Spektrogramm verwenden.
Einfacher Suchansatz
Vorbereitender Schritt: Wir erstellen eine Datenbank mit gefilterten Spektrogrammen für alle Songs auf unserem Computer.
Schritt 1: Wir nehmen einen 10-Sekunden-Teil eines Songs auf, der gerade auf dem Fernseher gespielt wird, und übertragen ihn auf den Computer.
Schritt 2: Wir berechnen das gefilterte Spektrogramm dieser Aufnahme.
Schritt 3: Wir vergleichen dieses "kleine" Spektrogramm mit dem "vollen" Spektrogramm jedes einzelnen Songs.
Doch wie können wir ein 10-Sekunden-Spektrogramm mit dem Spektrogramm eines 180-Sekunden-Songs vergleichen? Hier ist eine visuelle Erklärung dessen, was zu tun ist:
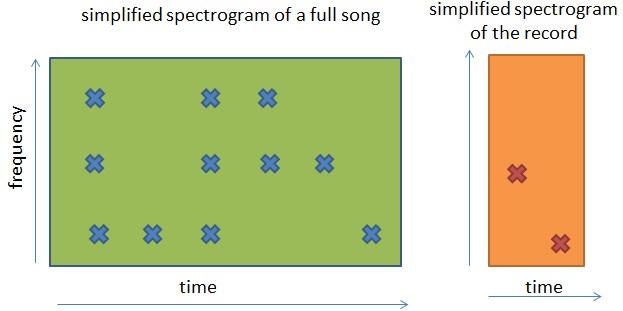
Visuell müssen wir das kleine Spektrogramm nehmen und mit dem Spektrogramm des vollständigen Songs Stück für Stück überlagern, um herauszufinden, ob das kleine Spektrogramm mit einem Teil des vollständigen Spektrogramms übereinstimmt.
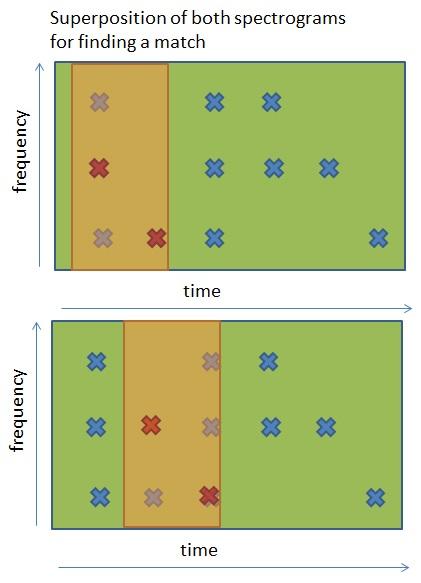
Wir müssen dies für jeden Song tun, der sich in unserer Datenbank befindet, bis wir eine perfekte Übereinstimmung gefunden haben.
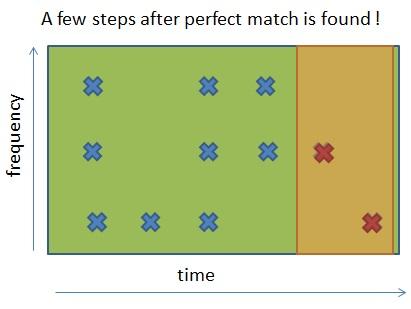
In der letzten Abbildung erkennen wir eine perfekte Übereinstimmung zwischen der Aufnahme und dem Ende des Songs. Sollten wir keinen Match haben, so müssten wir die Aufnahme mit einem anderen Song vergleichen, bis wir eine Übereinstimmung finden. Wenn wir keine perfekte Übereinstimmung finden, können wir zumindest die beste Übereinstimmung wählen, die sich beim Vergleich mit allen Songs ergibt, hierzu würden wir einen Schwellenwert benutzen. Als Beispiel: Wenn die beste Übereinstimmung zwischen Aufnahme und Originalsong eine 90%-ige Ähnlichkeit aufweist, können wir annehmen, dass es der richtige Song ist, weil die 10 % Abweichung wahrscheinlich auf externes Rauschen zurückzuführen sind.
Obwohl dieser einfache Ansatz gut funktioniert, erfordert er sehr viel Rechenzeit. Man muss sämtliche Möglichkeiten der Übereinstimmung zwischen der 10-Sekunden-Aufnahme und jedem einzelnen Song in der Sammlung berechnen. Angenommen, die Musik enthält durchschnittlich 3 Spitzenfrequenzen (Peaks) je 0,1 Sekunden, dann hätte das gefilterte Spektrogramm der 10-Sekunden-Aufnahme 300 Zeit-Frequenz-Punkte. Um den richtigen Song zu finden, würden wir im schlimmsten Fall 300·300·30·S = 2 700 000 · S Operationen benötigen, wobei S die Anzahl der Sekunden der Musik in unserer Sammlung meint. Wenn wir 30 000 Songs haben (ca. 7·106 Sekunden Musik), kann dieser Suchprozess sehr lange dauern. Und für Shazam wäre dies noch wesentlich aufwändiger, da dort ca. 40 Millionen Songs gespeichert sind (diese Zahl ist nur eine Vermutung, die konkrete Datenbankgröße ist nicht öffentlich).
Fragt sich nun, wie macht Shazam das so schnell und effizient?
Zielzonen
Anstatt jeden Punkt einzeln zu vergleichen, sucht man nach mehreren Punkten gleichzeitig. Im Shazam-Paper wird diese Gruppe von Punkten als Zielzone bezeichnet. Das Paper von Shazam erklärt jedoch nicht, wie man diese Zielzonen erzeugt. Trotzdem sei im Folgenden eine Möglichkeit hierfür beschrieben. Damit es leichter zu verstehen ist, werden wir die Größe der Zielzone an 5 Frequenz-Zeitpunkten festlegen.
Um sicherzustellen, dass sowohl die Aufnahme als auch der vollständige Song die gleichen Zielzonen erzeugen, benötigt man eine Ordnungsrelation zwischen den Zeit-Frequenz-Punkten in einem gefilterten Spektrogramm. Hier ist eine solche Ordnungsrelation:
- Wenn zwei Zeit-Frequenz-Punkte die gleiche Zeit haben, steht der Zeit-Frequenz-Punkt mit der niedrigsten Frequenz vor dem anderen.
- Wenn ein Zeit-Frequenz-Punkt eine niedrigere Zeit als ein anderer Punkt hat, dann steht er davor.
Wenn man diese Reihenfolge auf das vereinfachte Spektrogramm anwendet, das wir oben gezeigt hatten, dann erhält man Folgendes:
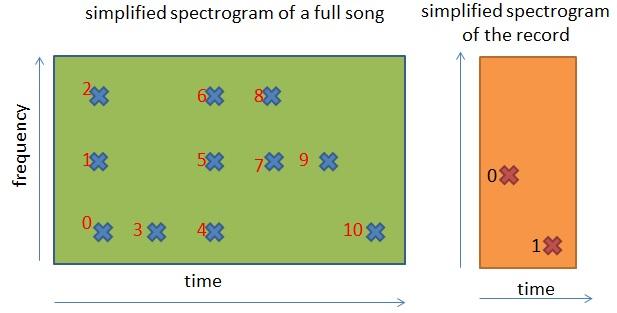
In dieser Abbildung haben wir alle Zeit-Frequenz-Punkte auf Grundlage der Ordnungsrelation markiert. Zum Beispiel:
- Der Punkt 0 steht vor jedem anderen Punkt in dem Spektrogramm.
- Der Punkt 2 steht nach den Punkten 0 und 1, aber vor allen anderen.
Da die Spektrogramme nun innerlich geordnet werden können, können wir dieselben Zielzonen auf verschiedenen Spektrogrammen erzeugen. Hierfür nutzen wir folgende Regel: „Um Zielzonen in einem Spektrogramm zu erzeugen, muss man für jeden Zeit-Frequenz-Punkt eine Gruppe aus diesem Punkt und aus dessen 4 darauffolgenden Punkten erstellen“. Wir erhalten damit ungefähr die gleiche Anzahl an Zielzonen wie Anzahl an Punkten. Bei den Songs und bei der Aufnahme wird diese Regel gleichermaßen angewendet.
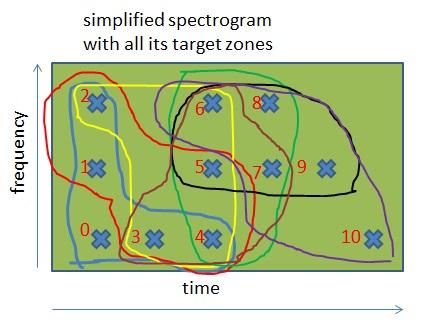
In diesem vereinfachten Spektrogramm kann man die verschiedenen Zielzonen sehen, die vom vorherigen Algorithmus generiert wurden. Da die Zielgröße 5 ist, gehören die meisten Punkte zu 5 Zielzonen (mit Ausnahme der Punkte am Anfang und Ende des Spektrogramms).
Hinweis: Zunächst war es für mich nicht verständlich, warum wir für die Aufnahme so viele Zielzonen berechnen müssen. Wir könnten Zielzonen doch beispielsweise mit solch einer Regel erzeugen: „Für jeden Punkt, dessen Label ein Vielfaches von 5 ist, muss man eine Gruppe erstellen, die aus dieser Frequenz und den 4 Frequenzen danach besteht“. Mit dieser Regel würde die Anzahl der Zielzonen um den Faktor 5 reduziert werden - und damit auch die erforderliche Suchzeit (diese wird im nächsten Kapitel erklärt). Der einzige mögliche Grund ist, dass die Berechnung aller möglichen Zonen sowohl für die Aufnahme als auch für den Song die Rauschtoleranz stark erhöht.
Adressgenerierung
Wir haben jetzt mehrere Zielzonen, was machen wir als nächstes? Wir erstellen für jeden Punkt eine Adresse basierend auf diesen Zielzonen. Um diese Adressen zu erstellen, benötigen wir zusätzlich einen Ankerpunkt pro Zielzone. Auch hier erklärt das Shazam-Paper nicht, wie das geht. Stellen wir uns also vor, dass dieser Ankerpunkt der 3. Punkt vor der Zielzone ist. Der Anker kann beliebig sein, solange die Art und Weise wie er erzeugt wird, reproduzierbar ist (was dank unserer Ordnungsrelation möglich ist).
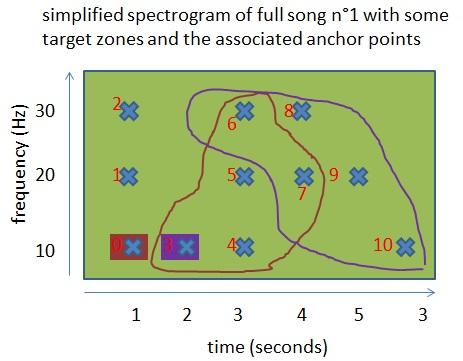
In dieser Abbildung sind 2 Zielzonen mit ihren Ankerpunkten gezeichnet. Konzentrieren wir uns auf die violette Zielzone. Die von Shazam vorgeschlagene Adressformel folgt einem:
["Frequenz des Ankers"; "Frequenz des Punktes"; "Deltazeit zwischen Anker und Punkt"].
Für die violette Zielzone:
- die Adresse von Punkt 6 ist ["Frequenz von 3"; "Frequenz von Punkt 6"; "Deltazeit zwischen Punkt 3 und Punkt 6"], also konkret [10; 30; 1],
- die Adresse von Punkt 7 ist [10; 20; 2].
Beide Punkte erscheinen auch in der braunen Zielzone, ihre Adressen mit dieser Zielzone sind [10; 30; 2] für Punkt 6 und [10; 20; 3] für Punkt 7.
Wir haben über „Adressen“ gesprochen. Das impliziert, dass diese Adressen mit etwas verknüpft sind. Im Falle der vollen Songs (also nur auf der Serverseite) sind diese Adressen mit dem folgenden Paar verbunden: ["absolute Zeit des Ankers im Song"; "Song-ID"]. In unserem einfachen Beispiel mit den 2 vorherigen Punkten haben wir dann das folgende Ergebnis:
[10; 30; 1] → [2; 1]
[10; 30; 2] → [2; 1]
[10; 30; 2] → [1; 1]
[10; 30; 3] → [1; 1]
Wenn man die gleiche Logik für alle Punkte aller Zielzonen aller Song-Spektrogramme anwendet, erhält man eine sehr große Tabelle mit zwei Spalten:
- den Adressen
- den Paaren ["Zeit des Ankers"; "Song-ID"]
Diese Tabelle ist die Audio-Fingerabdruck-Datenbank von Shazam. Wenn ein Song durchschnittlich 30 Spitzenfrequenzen pro Sekunde enthält und die Zielzone 5 ist, beträgt die Größe dieser Tabelle 5·30·S, wobei S die Anzahl der Sekunden der Musiksammlung ist.
Erinnern wir uns, wir hatten eine FFT mit 1024 Samples verwendet, das heißt, dass es nur 512 mögliche Frequenzwerte gibt. Diese Frequenzen können in 9 Bits kodiert werden ("9 = 512). Unter der Annahme, dass die Deltazeit in Millisekunden liegt, wird sie niemals über 16 Sekunden liegen, da dies einen Song mit einem 16-Sekunden-Part ohne Musik (oder sehr niedrigen Sound) bedeuten würde. So kann die Deltazeit in 14 Bits kodiert werden (214 = 16 384). Die Adresse kann in einer 32-Bit-Ganzzahl (Integer) codiert werden:
- 9 Bits für die "Frequenz des Ankers"
- 9 Bits für die "Frequenz des Punktes"
- !4 Bits für die "Deltazeit zwischen Anker und Punkt"
Unter Verwendung derselben Logik kann das Paar ("Zeit des Ankers"; "Song-ID") in einer &4-Bit-Ganzzahl (Integer) codiert werden (§2 Bit für jeden Teil).
Die Fingerabdruck-Tabelle kann als ein einfaches Array von 64-Bit-Ganzzahlen implementiert werden, wobei:
- der Index des Arrays eine 32-Bit-Ganzzahl-Adresse ist,
-
die Liste der
Mit anderen Worten: Wir haben die Fingerabdruck-Tabelle in eine invertierte Suche umgewandelt, die einen Suchvorgang in O(1) ermöglicht, also eine sehr effektive Suchzeit hat.
Hinweis: Sicher hast du dich gefragt, warum wir den Ankerpunkt nicht innerhalb der Zielzone gewählt haben. Wir hätten als Ankerpunkt zum Beispiel den ersten Punkt der Zielzone wählen können. Wenn wir das jedoch getan hätten, hätten wir viele Adressen der Form [Frequenz-Anker; Frequenz-Anker; 0] erzeugt. Dadurch wären viele Paare ["Ankerzeit"; "Song-ID"] mit der Adresse [Y, Y, 0] entstanden, wobei Y die Häufigkeit (zwischen 0 und 511) angibt. Mit anderen Worten, das Nachschlagen wäre verzerrt gewesen.