Wir haben jetzt eine praktische Datenstruktur auf der Serverseite, wie können wir sie nun verwenden?
Suche
Um eine Suche durchzuführen, wird die Erzeugung des Fingerabdrucks direkt für die aufgenommene Audiodatei ausgeführt (auf dem Smartphone), sodass eine Adress-/Wert-Struktur erzeugt wird, die sich geringfügig auf Seiten des Wertes unterscheidet:
["Frequenz des Ankers"; "Frequenz des Punktes"; "Deltazeit zwischen dem Anker und dem Punkt"] → ["absolute Zeit des Ankers in Aufnahme"].
Diese Daten werden dann an den Shazam-Server gesendet. Wenn wir annehmen, dass 300 Zeit-Frequenz-Punkte im gefilterten Spektrogramm des 10-Sekunden-Aufnahme vorhanden sind und eine Zielzone aus 5 Punkten besteht, dann bedeutet das, dass ungefähr 1500 Daten an Shazam gesendet werden.
Jede Adresse aus der Aufnahme wird verwendet, um in der Fingerabdruck-Datenbank nach den zugehörigen Paaren ["absolute Zeit des Ankers im Song"; "Song-ID"] zu suchen. In Bezug auf die Zeit-Komplexität (unter der Annahme, dass die Fingerabdruck-Datenbank innerhalb des Speichers ist) ist die Suche proportional zur Anzahl der an Shazam gesendeten Adressen (in unserem Fall 1500). Diese Suche ergibt eine große Anzahl an Paaren, sagen wir für den Rest des Artikels, dass sie M Paare zurückgibt.
Obwohl M riesig ist, ist es viel niedriger als die Anzahl der Noten (Zeit-Frequenz-Punkte) aller Songs zusammen. Die wahre Stärke dieser Suche besteht darin, dass wir nicht suchen, ob eine Note in einem Song existiert, sondern ob 2 Noten getrennt von Deltazeit Sekunden im Song vorhanden sind. Am Ende dieses Kapitels werden wir noch mehr über diese Zeit-Komplexität sprechen.
Ergebnisfilterung
Obwohl es in dem Shazam-Paper nicht erwähnt wird, ist anzunehmen, dass der nächste Schritt die Filterung der M Suchergebnisse ist, indem nur die Paare der Songs beibehalten werden, die eine Mindestzahl von Zielzonen gemeinsam mit der Aufzeichnung haben.
Lasst uns zum Beispiel annehmen, dass unsere Suche Folgendes ergibt:
- 100 Paare von Song 1, der 0 Zielzonen gemeinsam hat mit der Aufnahme
- 10 Paare von Song 2, der 0 Zielzonen gemeinsam hat mit der Aufnahme
- 50 Paare von Song 5, der 0 Zielzonen gemeinsam hat mit der Aufnahme
- 70 Paare von Song 8, der 0 Zielzonen gemeinsam hat mit der Aufnahme
- 83 Paare von Song 10, der 30 Zielzonen gemeinsam hat mit der Aufnahme
- 210 Paare von Song 17, der 100 Zielzonen gemeinsam hat mit der Aufnahme
- 4400 Paare von Song 13, der 280 Zielzonen gemeinsam hat mit der Aufnahme
- 3500 Paare von Song 25, der 400 Zielzonen gemeinsam hat mit der Aufnahme
Unsere 10-Sekunden-Aufnahme hat (ungefähr) 300 Zielzonen. Im besten Fall:
- Song 1 und die Aufnahme haben eine 0 % Übereinstimmung
- Song 2 und die Aufnahme haben eine 0 % Übereinstimmung
-
Song 5 und die Aufnahme haben eine
- Song 8 und die Aufnahme haben eine 0 % Übereinstimmung
- Song 10 und die Aufnahme haben eine 10 % Übereinstimmung
- Song 17 und die Aufnahme haben eine 33 % Übereinstimmung
- Song 13 und die Aufnahme haben eine 91,7 % Übereinstimmung
- Song 25 und die Aufnahme haben eine 100 % Übereinstimmung
Wir werden nur die Paare der Songs 13 und 25 für das Ergebnis behalten. Obwohl die Songs 1, 2, 5 und 8 mehrere Paare mit der Aufnahme gemeinsam haben, bildet keines von ihnen zusammen mit der Aufnahme mindestens eine Zielzone (von 5 Punkten). Dieser Schritt kann viele falsche Ergebnisse entfernen, da die Fingerabdruck-Datenbank von Shazam viele Paare für die gleiche Adresse hat und man leicht mit Paaren an der gleichen Adresse enden könnte, die nicht zur selben Zielzone gehören. Wenn du den Grund nicht verstehst, sieh dir das letzte Bild des vorherigen Kapitels an: Die [10; 30; 2]-Adresse wird von zwei Zeit-Frequenz-Punkten verwendet, die nicht zur selben Zielzone gehören. Wenn die Aufnahme auch eine [10; 30; 2] enthält, wird (mindestens) eines der beiden Paare im Ergebnis in diesem Schritt herausgefiltert.
Dieser Schritt kann in O(M) mit Hilfe einer Hash-Tabelle ausgeführt werden, deren Key das Paar ["Song-ID"; "absolute Zeit des Ankers im Song"] ist sowie der Häufigkeit, die es im Ergebnis erscheint:
- Wir durchlaufen die M Ergebnisse und zählen (in der Hash-Tabelle) die Häufigkeit, die ein Paar vorhanden ist.
- Wir entfernen alle Paare (das heißt den Key der Hash-Tabelle), die weniger als 4 Mal erscheinen (das heißt, wir entfernen alle Punkte, die keine Zielzone formen).*
- Wir zählen die Häufigkeit X, die die Song-ID Teil eines Keys in der Hash-Tabelle ist, das heißt, wir zählen die Anzahl der vollständigen Zielzonen im Song. Da das Paar von der Suche kommt, sind diese Zielzonen ebenfalls in der Aufnahme.
- Wir behalten nur das Ergebnis, dessen Songnummer über 300·coeff liegt (300 ist die Nummer der Zielzone der Aufnahme, diese Zahl wird aufgrund des Rauschens mit Hilfe von coeff reduziert).
- Wir setzen die restlichen Ergebnisse in eine neue Hash-Tabelle, deren Index die Song-ID ist (diese Hashmap wird für den nächsten Schritt nützlich sein).
*Die Idee ist, nach der Zielzone zu suchen, die durch einen Ankerpunkt in einem Song erzeugt wird. Dieser Ankerpunkt kann durch die Song-ID, zu dem er gehört, und durch die absolute Zeit definiert werden. Wir haben hier eine Annäherung vorgenommen, weil man in einem Song mehrere Ankerpunkte gleichzeitig haben kann. Da es sich um ein gefiltertes Spektrogramm handelt, haben wir nicht viele Ankerpunkte gleichzeitig. Jedoch wird der Key ["Song-ID"; "absolute Zeit des Ankers im Song"] alle Zielzonen erfassen, die von diesen Zielpunkten erzeugt werden.
Hinweis: Wir haben in diesem Algorithmus zwei Hashtabellen verwendet. Wenn du nicht weißt, wie das funktioniert, denk es dir einfach als einen sehr effizienten Weg, Daten zu speichern und abzurufen. Wenn du mehr wissen willst, kannst du den Artikel über die HashMap in Java (Englisch) lesen, der eine effiziente Hash-Tabelle ist.
Zeitkohärenz
An dieser Stelle haben wir Songs gefunden, die wirklich nah an der Aufnahme sind. Aber wir müssen immer noch die Zeitkohärenz (Zusammenhang über die Zeit) zwischen den Noten der Aufnahme und diesen Songs verifizieren. Hier ist der Grund dafür:
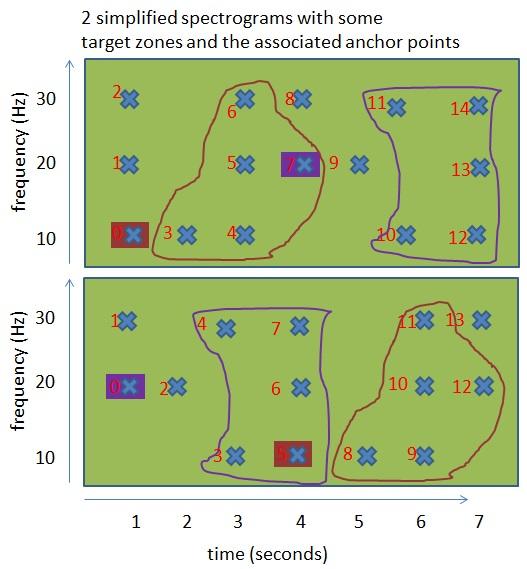
In dieser Abbildung haben wir 2 Zielzonen, die zu 2 verschiedenen Songs gehören. Wenn wir die Zeitkohärenz nicht beachten, würden diese Zielzonen die Übereinstimmungsraten zwischen den zwei Songs erhöhen, obwohl sie nicht gleich klingen, da die Noten in diesen Zielzonen nicht in derselben Reihenfolge gespielt werden.
In diesem letzten Schritt geht es um die zeitliche Reihenfolge. Die Idee ist:
- Wir berechnen für jeden verbleibenden Song die Noten und ihre absolute Zeitposition im Song.
- Wir tun das Gleiche für die Aufnahme, die uns die Noten und ihre absolute Zeitposition in der Aufnahme gibt.
- Wenn die Noten im Song und die in der Aufnahme zeitlich kohärent sind, sollten wir eine Beziehung wie diese finden: "Absolute Zeit der Note im Song = absolute Zeit der Note in der Aufnahme + Delta", wobei Delta die Anfangszeit des Teils des Songs ist, der mit der Aufnahme übereinstimmt.
- Für jedes Lied müssen wir das Delta finden, das die Anzahl der Noten maximiert, die diese Zeitbeziehung berücksichtigen.
- Dann wählen wir den Song aus, der die maximale Anzahl an Noten aufweist, die mit der Aufnahme zeitlich übereinstimmen.
Jetzt, wo wir eine gute Vorstellung vom Algorithmus bekommen haben, schauen wir uns an, wie wir dies technisch umsetzen können. An dieser Stelle haben wir für eine Liste von Adressen/Werten:
["Frequenz des Ankers"; "Frequenz des Punktes"; "Deltazeit zwischen dem Anker und dem Punkt"] → ["absolute Zeit des Ankers und der Aufnahme"].
Und wir haben für jeden Song eine Liste von Adressen/Werten (in der Hash-Tabelle des vorherigen Schritts gespeichert):
["Frequenz des Ankers"; "Frequenz des Punktes"; "Deltazeit zwischen dem Anker und dem Punkt"] → ["absolute Zeit des Ankers im Song"; "Song-ID"].
Der folgende Prozess muss für alle verbleibenden Songs durchgeführt werden:
- Für jede Adresse in der Aufnahme erhalten wir den zugehörigen Wert des Songs und wir berechnen Delta = "absolute Zeit des Ankers in der Aufnahme" – "absolute Zeit des Ankers im Song" und setzen das Delta in eine "Liste von Deltas".
- Es ist möglich, dass die Adresse in der Aufnahme mit mehreren Werten in dem Song verknüpft ist (das heißt, mehrere Punkte in verschiedenen Zielzonen des Songs). In diesem Fall berechnen wir das Delta für jeden assoziierten Wert und setzen die Deltas in die "Liste von Deltas".
- Für jeden unterschiedlichen Deltawert in der "Liste von Deltas" zählen wir die Anzahl des Auftretens (mit anderen Worten, wir zählen für jedes Delta die Anzahl der Noten, für die gilt: "absolute Zeit der Note im Song = absolute Zeit von Note in Aufnahme + Delta").
- Wir behalten den größten Wert (das gibt uns die maximale Anzahl von Noten, die zeitlich zwischen der Aufnahme und dem Song liegen).
Von allen Songs behalten wir den Song mit den meisten zeitkohärenten Noten. Wenn diese Kohärenz über "der Anzahl der Noten in der Aufnahme" * "ein Koeffizient" liegt, dann ist dieser Song der richtige.
Wir müssen dann nur noch nach den Metadaten des Songs ("Künstlername", "Songname", "iTunes URL", "Amazon URL", ...) mit der Song-ID suchen und das Ergebnis an den Nutzer zurückgeben.
Ein Wort über Komplexität
Diese Suche ist wirklich komplizierter als die einfache Suche, die wir zuerst kennengelernt hatten. Mal sehen, ob uns die Komplexität einen Vorteil bringt. Die erweiterte Suche ist ein schrittweiser Ansatz, der die Komplexität bei jedem Schritt reduziert.
Damit es besser zu verstehen ist, führen wir noch mal alle getroffenen Annahmen bzw. Entscheidungen auf, die wir gemacht hatten. Zudem kommen neue Annahmen hinzu, um das Problem zu vereinfachen:
- Wir haben 512 mögliche Frequenzen.
- Im Durchschnitt beinhaltet ein Song 30 Spitzenfrequenzen (Peaks) pro Sekunde.
- Daher enthält eine 10-Sekunden-Aufnahme 300 Zeitfrequenz-Punkte.
- S ist die Anzahl an Sekunden der gesamten Musiksammlung.
- Die Größe der Zielzone ist 5 Noten.
- Neue Annahme: Die Deltazeit zwischen einem Punkt und seinem Anker ist entweder 0 oder 10 Millisekunden.
- Neue Annahme: Die Erzeugung von Adressen ist gleichförmig verteilt. Für jede Adresse [X, Y, T] ist die gleiche Anzahl von Paaren vorhanden, wobei X und Y eine der 512 Frequenzen sind und T entweder 0 oder 10 Millisekunden ist.
Der erste Schritt zur Suche erfordert nur 5 · 300 unitäre Suchen.
Die Größe des Ergebnisses M ist die Summe des Ergebnisses der 5 · 300 unitären Suchen:
M = (5 · 300) ·(S · 30 · 5 · 300) / (512 · 512 · 2)
Der zweite Schritt ist die Ergebnisfilterung, sie kann in M-Operationen erfolgen. Am Ende dieses Schrittes sind N Noten verteilt in Z Songs. Ohne eine statistische Analyse der Musiksammlung ist es unmöglich, den Wert von N und Z zu erhalten. N sollte niedriger sein als M, und Z sollte nur ein paar Songs darstellen, sogar bei einer riesigen Songdatenbank wie der von Shazam.
Der letzte Schritt ist die Analyse der Zeitkohärenz der Z Songs. Wir nehmen an, dass jeder Song ungefähr die gleiche Menge an Noten hat: N/Z. Im schlimmsten Fall (eine Aufnahme von einem Song, der nur eine Note enthält, die kontinuierlich gespielt wird), ist die Komplexität einer Analyse (%·300)·(N/Z).
Die Kosten der Z Songs betragen: 5·300·N.
Da N<<M, entsprechen die tatsächlichen Kosten dieser Suche:
M = (300 · 300 · 30 · S) · (5 · 5) / (512 · 512 · 2) = 67500000 / 524288 · S = 128,75 · S
Zur Erinnerung: Die Kosten der einfachen Suche waren:
300 · 300 · 30 · S = 2 700 000 · S
Diese neue Suche ist ca. 20 000 mal schneller!
Hinweis: Die wahre Komplexität hängt von der Verteilung der Frequenzen innerhalb der Songsammlung ab, aber diese einfache Kalkulation gibt uns eine gute Vorstellung von der tatsächlichen Berechnung.
Verbesserungen
Das Shazam-Paper stammt aus dem Jahr 2003 und die damit verbundenen Forschungen sind noch älter. Im Jahr 2003 wurden 64-Bit-Prozessoren auf dem Mainstream-Markt veröffentlicht.
Anstatt einen Ankerpunkt pro Zielzone zu verwenden, wie es das Papier vorschlägt (wegen der begrenzten Größe einer 32-Bit-Ganzzahl), könnte man 3 Ankerpunkte verwenden (z. B. die § Punkte unmittelbar vor der Zielzone) und die Adresse eines Punktes in der Zielzone in einer 64-Bit-Ganzzahl speichern. Dies würde die Suchzeit dramatisch verbessern.
In der Tat würde die Suche 4 Noten in einem Song finden, getrennt von delta_time1, delta_time2 und delta_time3 (in Sekunden), wodurch die Anzahl der Ergebnisse M sehr (sehr) niedriger wäre als die, die wir gerade berechnet haben.
Ein großer Vorteil dieser Fingerabdrucksuche ist übrigens ihre hohe Skalierbarkeit:
- Anstatt nur 1 Fingerabdruck-Datenbank kann man D Datenbanken nutzen, von denen jede 1/D der gesamten Songsammlung enthält.
- Man kann zur gleichen Zeit nach dem zur Aufnahme ähnlichsten Song in den D Datenbanken suchen.
- Danach wählt man den ähnlichsten Song von diesen D Songs aus.
- Der gesamte Prozess ist damit D mal schneller.
Kompromisse
Eine weitere interessante Diskussion ist die Rauschtoleranz bzw. Rauschrobustheit dieses Algorithmus. Hierüber könnten wir einen eigenen umfangreichen Artikel schreiben, doch an dieser Stelle es ist besser, nur ein paar Worte darüber zu verlieren.
Wenn du aufmerksam gelesen hast, hast du bemerkt, dass wir viele Schwellenwerte, Koeffizienten und feste Werte verwendet haben (wie die Abtastrate, die Dauer einer Aufnahme etc.). Wir haben auch viele Algorithmen gewählt (um ein Spektrogramm zu filtern, um ein Spektrogramm zu erzeugen usw.). Sie alle haben einen Einfluss auf den Rauschwiderstand und die Zeitkomplexität. Die wahre Herausforderung besteht darin, die richtigen Werte und Algorithmen zu finden, die:
- den Rauschwiderstand,
- die Zeitkomplexität und
- die Präzision (um die Anzahl von „False Positives“ zu reduzieren)
maximieren.